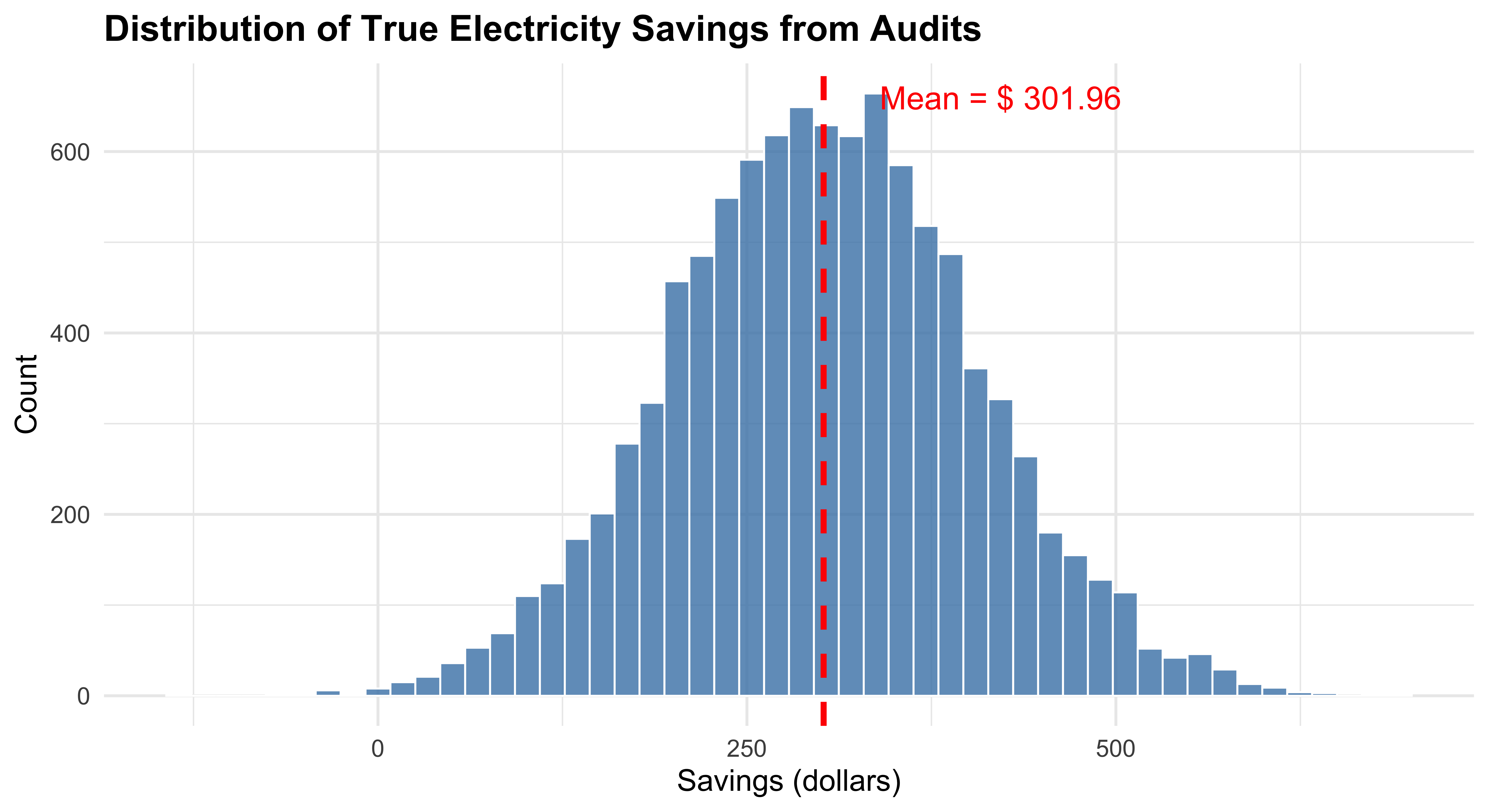
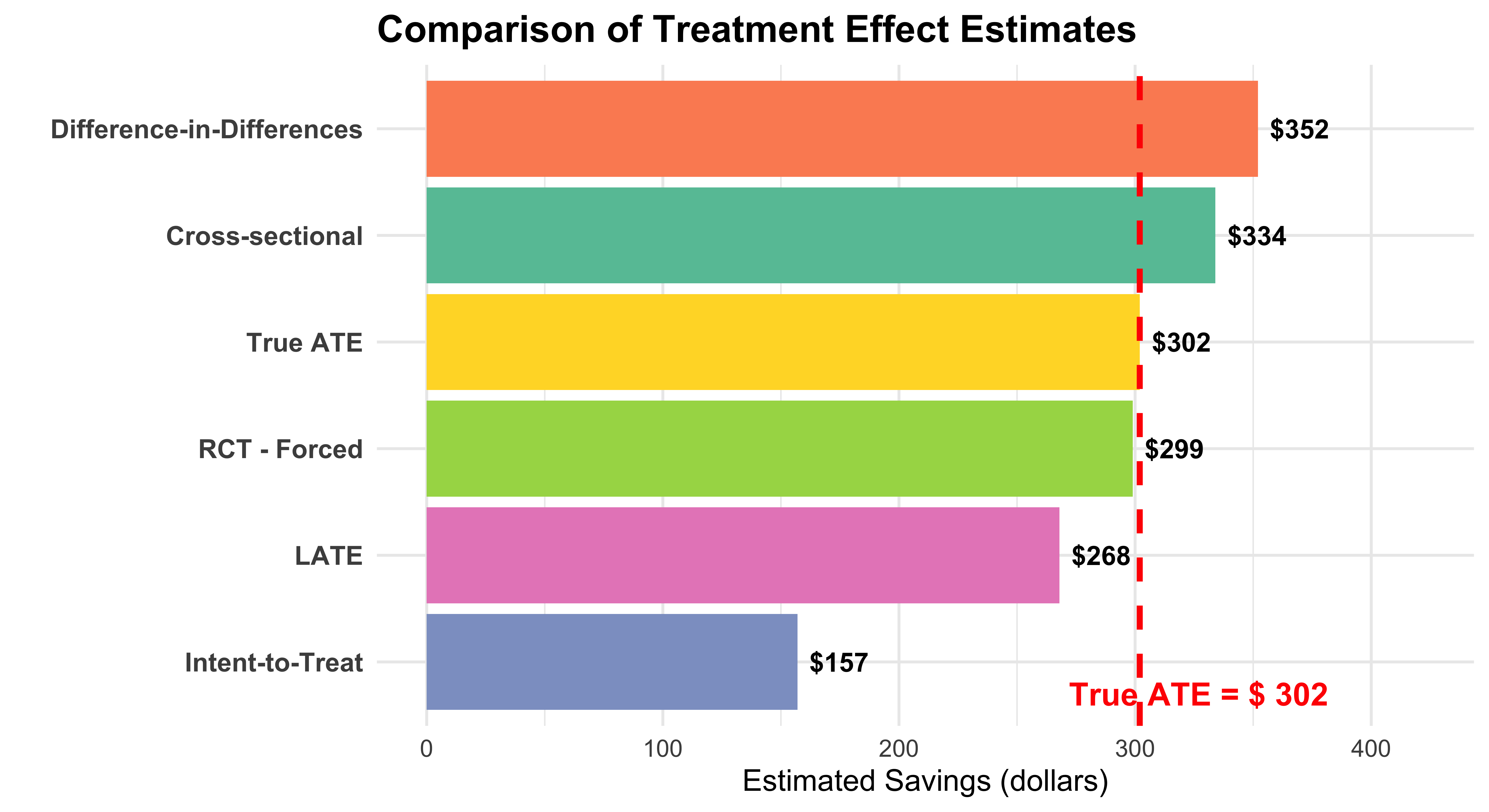
Show code
# Load the data
# audit_data <- read_csv(file.path(root,"_old", "_problem_sets",
# "pset_energy-efficiency","audit_data_lowercase.csv"))
audit_data <- read_csv(file.path(root,"modules", "EnergyEfficiency", "practice_problems",
"old_pset","audit_data_lowercase.csv"))
# Display first few rows
head(audit_data, 4) %>%
kable(caption = "First 4 rows of audit data") %>%
kable_styling(font_size = 20)| household | y00 | y10 | y11 | ey10 | ey11 | hassle |
|---|---|---|---|---|---|---|
| 1 | 1251.248 | 1874.361 | 1548.779 | 1843.381 | 1486.276 | 99.83278 |
| 2 | 1418.414 | 2129.128 | 1786.575 | 2151.938 | 1830.218 | 70.99882 |
| 3 | 1549.773 | 2099.195 | 1646.176 | 2165.068 | 1648.257 | 111.12599 |
| 4 | 1255.664 | 1922.626 | 1548.693 | 1963.576 | 1570.199 | 101.88632 |